Did you forget to allocate Huge Pages on your PostgreSQL server?
This short post is for those who answered ‘keep the default’ in the following. Because the default (which is no huge page allocated) is not good for a database.
When you install a Linux server, by default, there are no Huge Pages defined until you set vm.nr_hugepages in /etc/sysctl.conf and reboot or ‘sysctl -p’.
When you install PostgreSQL, by default, huge_pages=try which means that the postgres server will start with no error nor warning when huge pages are not available. This is mostly the equivalent of ‘LARGE_PAGES=TRUE’ in Oracle, except that Oracle will try to allocate as much as possible in Huge Pages.
This setting can be considered safer in case of unplanned reboot: prefer starting in degraded mode rather than not starting at all. But the risk is that you do not realize when the shared buffers are allocated in small pages.
Where?
First, how to know if the shared buffers were allocated in small or large pages? They are shared, and then show in pmap with ‘s’ mode. Here is my pmap output when allocated as Huge Pages:
$ pmap $(pgrep postgres) | grep -E -- "-s- .*deleted" | sort -u
00007fa05d600000 548864K rw-s- anon_hugepage (deleted)Here is the same when allocated as small pages:
$ pmap $(pgrep postgres) | grep -E -- "-s- .*deleted" | sort -u
00007f129b289000 547856K rw-s- zero (deleted)As far as I know, there’s no partially allocated shared buffer: if there are not enough huge pages for the total, then none are used.
How?
In order to set it, that’s easy. You set the number of 2MB pages in /etc/sysctl.conf and allocate with ‘sysctl -p’. Here is how I check the size of the memory area, from /proc/meminfo but formatted for humans.
How much? That’s simple: Enough and not too much.
Enough means that all shared buffers should fit. Just take the sum of all shared_buffers for all instances in the server. If you have other programs using shared memory and allocating it large pages, they count as well. And don't forget to update when you add a new instance or increase the memory for an existing one.
Not too much because the processes also need to allocate their memory as small pages and what is reserved for huge pages cannot be allocated in small pages. If you do not leave enough small pages, you will have many problems and may even not be able to boot. Like this:
In addition to that, PostgreSQL does not support direct IO and needs some free memory for the filesystem cache, which are small pages. The documentation still mentions that postgres shared buffers should leave the same amount of RAM for filesystem cache (which means double buffering).
Be careful, when looking at /proc/meminfo the Huge Pages allocated by postgreSQL are free until they are used. So do not rely on HugePages_Free do your maths from the sum of shared_buffers. Use pmap to see that they are used just after starting the instance. There may be some other kernel settings to set (permissions, memlock) if allocation didn’t occur.
Why?
Do not fear it. Once you have set those areas, and checked them, they are fixed. Then no surprise if you take care. And it can make a big difference in the performance and memory footprint. The shared buffers have the following properties:
- they are big, and allocating 1GB, 10GB or 100GB in 4k pages is not reasonable. Huge Pages are 2MB.
- they are shared, and mapping so many small pages from many processes is not efficient. Takes lot of memory just to map them, increases the chance of TLB misses,…
I’ll use Kevin Closson pgio (https://kevinclosson.net) to show how to test.
Here’s my pgio.conf:
$ grep -vE "^[[:blank:]]*#|^$" pgio.conf
UPDATE_PCT=0
RUN_TIME=60
NUM_SCHEMAS=2
NUM_THREADS=2
WORK_UNIT=255
UPDATE_WORK_UNIT=8
SCALE=100M
DBNAME=pgio
CONNECT_STRING=pgio
CREATE_BASE_TABLE=TRUE$ sh ./setup.shJob info: Loading 100M scale into 2 schemas as per pgio.conf->NUM_SCHEMAS.
Batching info: Loading 2 schemas per batch as per pgio.conf->NUM_THREADS.
Base table loading time: 0 seconds.Waiting for batch. Global schema count: 2. Elapsed: 0 seconds.
Waiting for batch. Global schema count: 2. Elapsed: 1 seconds.Group data loading phase complete. Elapsed: 1 seconds.
I have set up two 100M schemas. My shared_buffers is 500MB so all reads are cache hits:

2.7 million LIOPS (Logical Reads Per Second) here. The advantage of pgio benchmark is that I focus exactly on what I want to measure: reading pages from the shared buffer. There’s minimal physical I/O here (should be zero but there was no warm up here and the test is too short), and minimal processing on the page (and this is why I use pgio and not pgbench here).
I have disabled Huge Pages for this test.
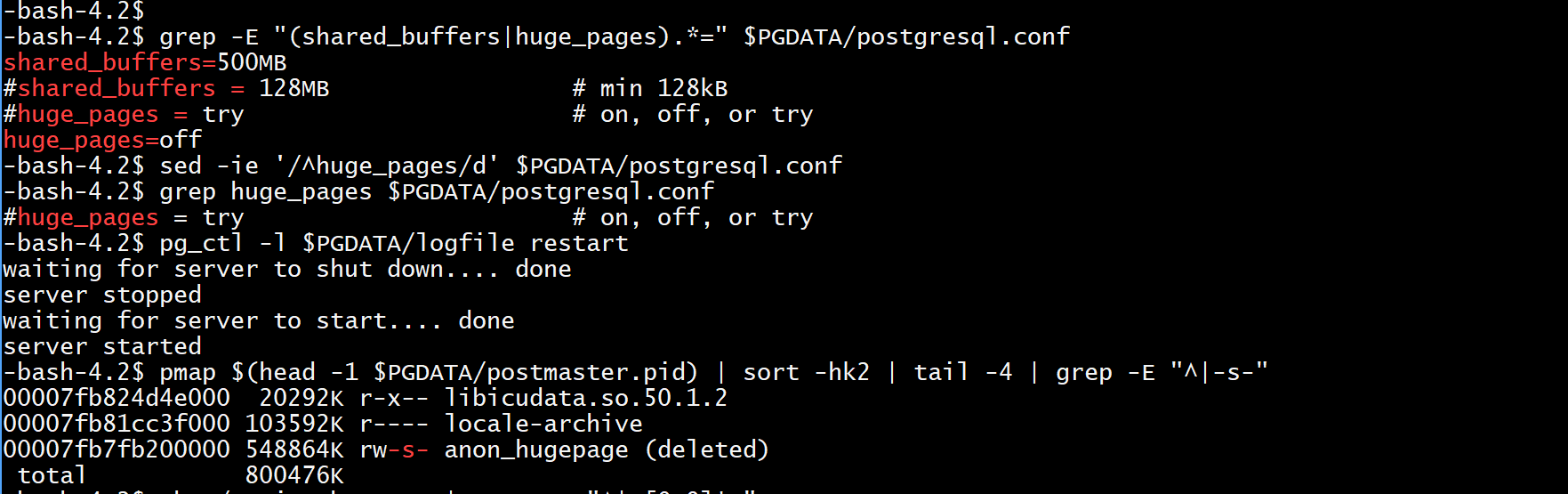
$ grep -E "(shared_buffers|huge_pages).*=" $PGDATA/postgresql.conf
shared_buffers=500MB
#shared_buffers = 128MB # min 128kB
#huge_pages = try # on, off, or try
huge_pages=offNow enabling them. I keep the ‘try’ default and check that they are used. I could have set huge_pages to true to be sure.
$ sed -ie '/^huge_pages/d' $PGDATA/postgresql.conf
$ grep huge_pages $PGDATA/postgresql.conf
#huge_pages = try # on, off, or try$ pg_ctl -l $PGDATA/logfile restart
waiting for server to shut down.... done
server stopped
waiting for server to start.... done
server started$ pmap $(head -1 $PGDATA/postmaster.pid) | sort -hk2 | tail -4 | grep -E "^|-s-"
00007fb824d4e000 20292K r-x-- libicudata.so.50.1.2
00007fb81cc3f000 103592K r---- locale-archive
00007fb7fb200000 548864K rw-s- anon_hugepage (deleted)
total 800476K
Then I run the same test:

Here, even with a small shared memory (500MB) and only 4 threads, the difference is visible: the cache hits performance on the small pages is only 2719719/3016865=90% of what is achieved with large pages.
Those screenshots are from a very small demo to demonstrate how to do it. If you need real numbers, run this on a longer run, like RUN_TIME=600. And on your platform, because of the overhead of large shared memory allocated in small pages depends on your CPU, your OS (with the patches to mitigate the CPU security vulnerabilities), your hypervisor,…
One thing is certain: any database shared buffer cache should be allocated in pages larger than the default. Small (4k) pages are not there for large allocations of shared areas above GigaBytes. And the second advantage is that they will never be written to swap: you allocate this memory to reduce disk I/O, and consequently, you don’t want it to be written to disk.
There’s a very nice presentation on this topic by Fernando Laudares Camargos:
