MVCC in Oracle vs. PostgreSQL, and a little no-bloat beauty
Databases that are ACID compliant must provide consistency, even when there are concurrent updates.
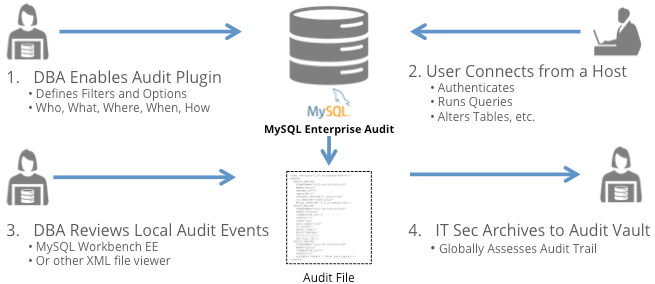
Let’s take an example:
- at 12:00 I have 1200$ in my account
- at 12:00 My banker runs long report to display the accounts balance. This report will scan the ACCOUNT tables for the next 2 minutes
- at 12:01 an amount of 500$ is transferred to my account
- at 12:02 the banker’s report has fetched all rows
What balance is displayed in my banker’s report?
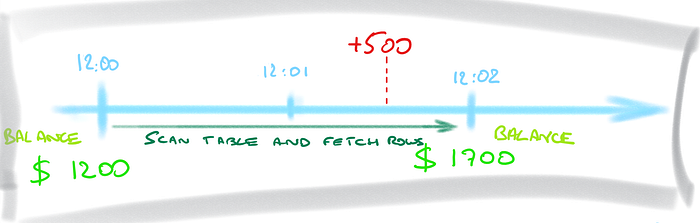
You may want to display $1700 because, at the time when the result is returned, the + $500 transaction has been received. But that’s impossible because the blocks where this update happened may have already been read before the update was done. You need all reads to be consistent as-of the same point-in-time and because the first blocks were read at 12:00 the only consistent result is the one from 12:00, which is $1200.
But there are two ways to achieve this, depending on the capabilities of the query engine:
- When only the current version of blocks can be read, the updates must be blocked until the end of the query, so that the update happens only at 12:02 after the report query terminates. Then reading the current state is consistent:

It seems that you see data as-of the end of the query, but that’s only a trick. You still read data as-of the beginning of the query. But you blocked all changes so that it is still the same at the end of the query. What I mean here is that you never read all the current version of data. You just make it current by blocking modifications.
- When the previous version can be read, because the previous values are saved when an update occurs, the + $500 update can happen concurrently. The query will read the previous version (as of 12:00):
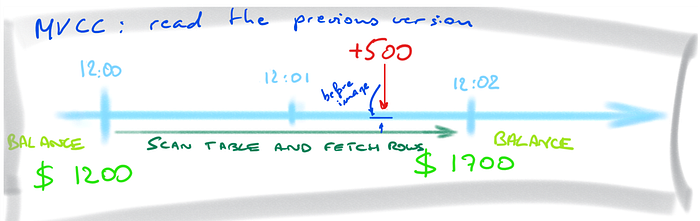
Here, you don’t see the latest committed values, but you can read consistent values without blocking any concurrent activity. If you want to be sure that it is still the current value (in a booking system for example), you can explicitly block concurrent changes (like with a SELECT FOR READ or SELECT FOR UPDATE). But for a report, obviously, you don’t want to block the changes.
The former, blocking concurrent modifications, is simpler to implement but means that readers (our banker’s report) will block writers (the transaction). This is what was done by DB2, or SQL Server by default and the application has to handle this with shorter transactions, deadlock prevention, and no reporting. I say “by default” because all databases are now trying to implement MVCC.
The latter, MVCC (Multi-Version Concurrency Control), is better for multi-purpose databases as it can handle OLTP and queries at the same time. For this, it needs to be able to reconstruct a previous image of data, like snapshots, and is implemented for a long time by Oracle, MySQL InnoDB and PostgreSQL.
But their implementation is completely different. PostgreSQL is versioning the tuples (the rows). Oracle does it a lower level, versioning the blocks where the rows (and the index entries, and the transaction information) are stored.
PostgreSQL tuple versioning
PostgreSQL is doing something like a Copy-On-Write. When you update one column of one row, the whole row is copied to a new version, probably in a new page, and the old row is also modified with a pointer to the new version. The index entries follow the same: as there is a brand new copy, all indexes must be updated to address this new location. All indexes, even those who are not concerned by the column that changed, are updated just because the whole row is moved. There’s an optimization to this with HOT (Heap Only Tuple) when the row stays in the same page (given that there’s enough free space).
This can be fast, and both commit or rollback is also fast. But this rapidity is misleading because more work will be required later to clean up the old tuples. That’s the vacuum process.
Another consequence with this approach is the high volume of WAL (redo log) generation because many blocks are touched when a tuple is moved to another place.
Oracle block versioning
Oracle avoids moving rows at all price because updating all indexes is often not scalable. Even when a row has to migrate to another block, Oracle keeps a pointer (chained rows) so that the index entries are still valid. That’s only when the row size increases and doesn’t fit anymore in the block. Instead of Copy-on-Write, the current version of the rows is updated in-place and the UNDO stores, in a different place, the change vectors that can be used to re-build a previous version of the block.
The big advantage here is that there’s no additional work needed to keep predictable performance on queries. The table blocks are clean and the undo blocks will just be reused later.
But there’s more. The index blocks are also versioned in the same way, which means that a query can still do a true Index Only scan even when there are concurrent changes. Oracle is versioning the whole blocks, all datafile blocks, and a query just builds the consistent version of the blocks when reading them from the buffer cache. The blocks, table or index ones, reference all the transactions that made changes in the ITL (Interested Transaction List) so that the query can know which ones are committed or not. This still takes minimum space: no bloat.
No-Bloat demo (Oracle)
Here is a small demo to show this no-bloat beauty. The code and the results explained is after the screenshot.
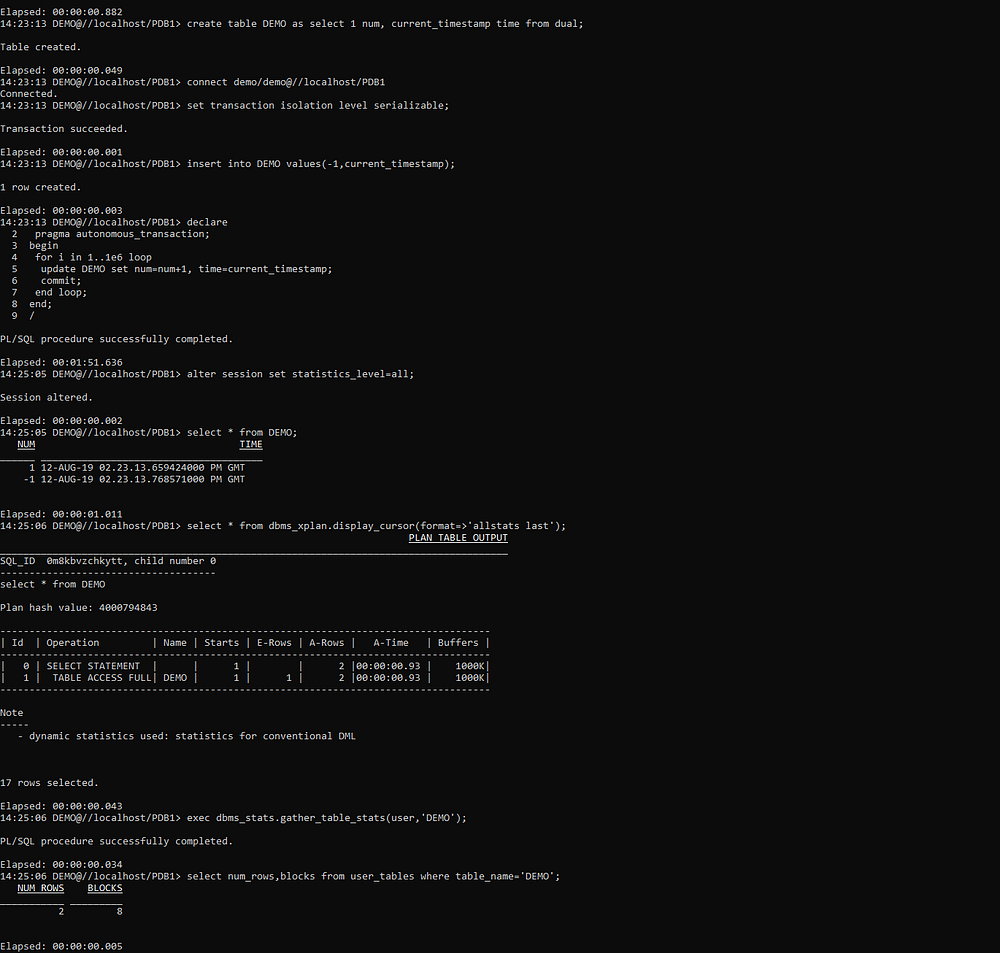
I create a table with a number and a timestamp, initialized with the value “1”
14:23:13 SQL> create table DEMO
as select 1 num, current_timestamp time from dual;Table created.
I start a transaction in SERIALIZABLE (which actually means SNAPSHOT) isolation level:
14:23:13 SQL> connect demo/demo@//localhost/PDB1
Connected.
14:23:13 SQL> set transaction isolation level serializable;Transaction succeeded.Elapsed: 00:00:00.001
I insert one row with value “-1”.
14:23:13 SQL> insert into DEMO values(-1,current_timestamp);1 row created.Elapsed: 00:00:00.003
Please remember that I do not commit this change. I am still in the serializable transaction.
Now, on other transactions, I’ll increase the value 1 million times. Because in Oracle we have autonomous transactions, I do it from there but you can do it from another session as well.
14:23:13 SQL> declare
2 pragma autonomous_transaction;
3 begin
4 for i in 1..1e6 loop
5 update DEMO set num=num+1, time=current_timestamp;
6 commit;
7 end loop;
8 end;
9 /PL/SQL procedure successfully completed.Elapsed: 00:01:51.636
This takes about 2 minutes. As I explained earlier, for each change the previous value is stored in the UNDO, and the status of the transaction is updated to set it to committed.
Now, I’m back in my serializable transaction where I still have the value “-1” uncommitted, and the value “1” committed before. Those are the two values that I expect to see: all committed ones plus my own transaction changes.
14:25:05 SQL> alter session set statistics_level=all;Session altered.Elapsed: 00:00:00.002
14:25:05 SQL> select * from DEMO;
NUM TIME
______ ______________________________________
1 12-AUG-19 02.23.13.659424000 PM GMT
-1 12-AUG-19 02.23.13.768571000 PM GMTElapsed: 00:00:01.011
Perfect. One second only. The 1 million changes that were done and committed after the start of my transaction are not visible, thanks to my isolation level. I explained that Oracle has to read the UNDO to rollback the changes in a clone of the block, and check the state of the transactions referenced by the ITL in the block header. This is why I can see 1 million accesses to buffers:
14:25:06 SQL> select * from dbms_xplan.display_cursor(format=>'allstats last');
PLAN_TABLE_OUTPUT
____________________________________________________________________
SQL_ID 0m8kbvzchkytt, child number 0
-------------------------------------
select * from DEMOPlan hash value: 4000794843--------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | Buffers |
--------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2 | 1000K|
| 1 | TABLE ACCESS FULL| DEMO | 1 | 2 | 1000K|
--------------------------------------------------------------Elapsed: 00:00:00.043
This is still fast because this fit in only few blocks, the same set of buffers is accessed multiple time and then stay in cache.
Now, here is the nice part. My table is still very small (8 blocks — that’s 16KB):
14:25:06 SQL> commit;Commit complete.Elapsed: 00:00:00.00414:25:06 SQL> exec dbms_stats.gather_table_stats(user,'DEMO');PL/SQL procedure successfully completed.Elapsed: 00:00:00.034
14:25:06 SQL> select num_rows,blocks from user_tables where table_name='DEMO';
NUM_ROWS BLOCKS
___________ _________
2 8Elapsed: 00:00:00.005
14:25:06 SQL> exit
For sure, the previous values are all stored in the UNDO and do not take any space in the table blocks. But I said that Oracle has to check all the one million ITL entries. This is how my session knows that the value “-1” was done by my session (and then visible even before commit), that the value “-1” was committed before my transaction start, and that all the other updates were committed after the start of my transaction, from another transaction.
The status is stored in the UNDO transaction table, but the ITL itself takes 24 bytes to identify the entry in the transaction table. And the ITL is stored in the block header. But you cannot fit 1 million of them in a block, right?
The magic is that you don’t need to store all of them because all those 1 million transactions were not active at the same time. When my SELECT query reads the current block, only the last ITL is required: the one for the 1000000th change. With it, my session can go to the UNDO, rebuild the previous version of the block, just before this 1000000th change. And, because the whole block is versioned, including its metadata, the last ITL is now, in this consistent read clone, related to the 999999th change. You get the idea: this ITL is sufficient to rollback the block to the 999998th change…