UUID (aka GUID) vs. Oracle sequence number
When you want to generate a unique number, for a primary key, the most common idea (and the right one) is to get a number from an always increasing generator. Oracle provides SEQUENCE for this purpose, which is optimized, easy to use and scalable.
But some application developer has the idea to use a UUID (Universally Unique Identifier) also known as GUID (Globally Unique Identifier). The main advantage is that you do not need a shared object like a sequence because there is no need for a central authority. UUID is generated with a hash function on some local identifiers (host, process, thread) and the hash value is large enough to reduce the probability of collisions without the need for a shared central authority.
However, in the context of Oracle Database:
- having a shared object is not a problem, as we have a database
- large values are less efficient (more space in disk, memory and more CPU to process)
NUMBER from SEQUENCE
In order to put some numbers about this argument, I create a 10 million rows table with an ID generated from a SEQUENCE:
SQL> create sequence DEMO_NUM_ID cache 1e6;
Sequence DEMO_NUM_ID created.SQL> create table DEMO_NUM
(ID constraint DEMO_NUM_ID primary key, NUM)
as select DEMO_NUM_ID.nextval, rownum
from xmltable('1 to 10000000');Table DEMO_NUM created.
Elapsed: 00:04:37.796
The data type returned by the sequence is a NUMBER:
SQL> desc DEMO_NUMName Null? Type
---- -------- ----------
ID NOT NULL NUMBER(38)
NUM NUMBER
A NUMBER stores two digits per bytes. Here, my 10 million values take on average less than 5 bytes:
SQL> select sum(vsize(ID))/count(*),max(ID),count(*) from DEMO_NUM;SUM(VSIZE(ID))/COUNT(*) MAX(ID) COUNT(*)
----------------------- ---------- ----------
4.8888893 10000000 10000000
This is very efficient. It is even smaller than a ROWID which is the internal identification of a row.
UUID from SYS_GUID()
Here is a similar table with the ID generated as a GUID:
SQL> create table DEMO_GUID
(ID constraint DEMO_GUID_ID primary key, NUM)
as select sys_guid(), rownum
from xmltable('1 to 10000000');Table DEMO_GUID created.
Elapsed: 00:05:45.900
You can already see that it takes longer to generate. This generates a RAW datatype in 16 bytes.
SQL> desc DEMO_GUID
Name Null? Type
---- -------- ------------
ID NOT NULL RAW(16 BYTE)
NUM NUMBERThis is very large. Each row where it is a primary key, and each foreign key, and indexes on them, will take 16 bytes where a large part is always the same (hashed from the host, and process). Note that a RAW is displayed with its hexadecimal character translation which is 32 characters here, but does not store it as a VARCHAR2(32) as this will be 2 times larger, and has some additional processing for characterset.
No surprise here, each value is 16 bytes:
SQL> select sum(vsize(ID))/count(*) from DEMO_GUID;SUM(VSIZE(ID))/COUNT(*)
-----------------------
16
RAW from NUMBER
I see only one advantage in GUID primary keys: they are RAW datatypes. I like it because we don’t want arithmetic operations on it. And in addition to that nobody will complain about gaps in numbering. Then, can we store our NUMBER from the sequence as a ROW?
Here, I’m converting to a varchar2 hexadecimal and then to a raw. There’s probably a more efficient method to convert a number to a binary row. UTL_RAW has a CAST_FROM_NUMBER but that is the NUMBER representation. There’s also a CAST_FROM_BINARY_INTEGER. Here, I did a simple conversion through a varchar2, not very nice but the execution time is correct.
SQL> create sequence DEMO_RAW_ID cache 1e6;
Sequence DEMO_RAW_ID created.SQL> create table DEMO_RAW
(ID constraint DEMO_RAW_ID primary key, NUM)
as select hextoraw(to_char(DEMO_RAW_ID.nextval,rpad('FM',65,'X')))
, rownum
from xmltable('1 to 10000000');Table DEMO_RAW created.
Elapsed: 00:04:21.259
This storage is even smaller than the NUMBER. 3 bytes instead of 5 bytes on average for those 10 million values:
SQL> select * from
(select sum(vsize(ID))/count(*) "vsize(NUM)" from DEMO_NUM),
(select sum(vsize(ID))/count(*) "vsize(RAW)" from DEMO_RAW),
(select sum(vsize(ID))/count(*) "vsize(GUID)" from DEMO_GUID);vsize(NUM) vsize(RAW) vsize(GUID)
---------- ---------- -----------
4.8888893 2.993421 16
This is totally expected as a byte can store 255 different values, but NUMBER uses only 99 ones with the two digits representation. In my opinion, it would make sense to have a SEQUENCE returning an integer as a RAW binary representation. But as I don’t think people will actually use it, I will not fill an Enhancement Request for that.
Here is the size for the tables and the index on this ID column:
SQL> select segment_name,segment_type,bytes/1024/1024 MBytes
from dba_segments
where owner=user and segment_name like 'DEMO%' order by mbytes;SEGMENT_NAME SEGMENT_TYPE MBYTES
------------------------------ ------------------ ----------
DEMO_RAW_ID INDEX 160
DEMO_RAW TABLE 168
DEMO_NUM_ID INDEX 174
DEMO_NUM TABLE 188
DEMO_GUID_ID INDEX 296
DEMO_GUID TABLE 304
Of course, this confirms what we have seen with the average size. The GUID is definitely not a good solution.
Compression
12cR2 introduced a compression algorithm for indexes which is interesting even when there are no repeated column values: ADVANCED HIGH (which is available in Enterprise Edition with Advanced Compression Option):
SQL> alter index DEMO_GUID_ID rebuild compress advanced high;Index DEMO_GUID_ID altered.
Elapsed: 00:01:30.035SQL> alter index DEMO_RAW_ID rebuild compress advanced high;Index DEMO_RAW_ID altered.
Elapsed: 00:00:57.193SQL> alter index DEMO_NUM_ID rebuild compress advanced high;Index DEMO_NUM_ID altered.
Elapsed: 00:00:49.574
This reduced all 3 indexes. But the GUID one is still the largest one even if a large part of the values are repeated.
SQL> select segment_name,segment_type,bytes/1024/1024 MBytes from dba_segments where owner=user and segment_name like 'DEMO%' order by mbytes;SEGMENT_NAME SEGMENT_TYPE MBYTES
------------------------------ ------------------ ----------
DEMO_RAW_ID INDEX 80
DEMO_NUM_ID INDEX 80
DEMO_GUID_ID INDEX 136
DEMO_RAW TABLE 168
DEMO_NUM TABLE 188
DEMO_GUID TABLE 304
It is interesting to see that the benefit of RAW number vs. NUMBER datatype is smaller once compressed.
When is GUID smaller than a NUMBER?
Here is where a NUMBER starts to be larger than a 16 bytes GUID:
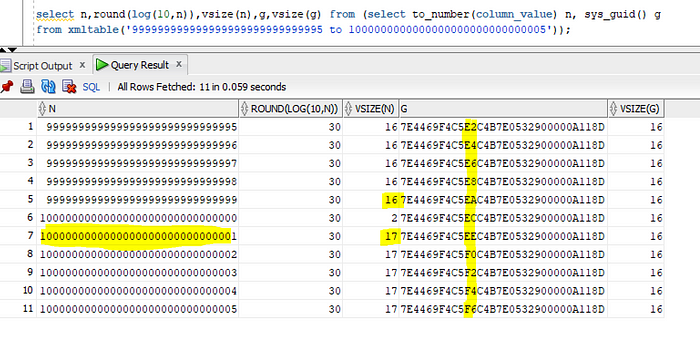
1E30+1 is the first number that reaches 17 bytes. You will never reach this number with a sequence. Just calculate the size of a database storing these numbers — even with huge gaps in the sequences. That’s impossible. And anyway, GUID is not a solution there given the high probability of collisions.
In summary: do not use GUID or UUID for your primary keys.
A NUMBER generated from a SEQUENCE is the right/efficient/scalable way to get a unique identifier. And if you want to be sure to have no collision when merging or replicating from another system, then just add another ‘system identifier’ as an additional column in the primary key. This can be a node number in a distributed system, or a 3-letter identifier of the company. When column values have a repeated subset, there’s no efficient deduplication or compression techniques. But when it is a different column that is fully repeated, table and index compression can be used. So, if you really need to add a hashed hostname, put it in an additional column rather than the UUID idea of mixing all in one value.
